typeahead? more like typebehind! amirite

typeahead.waow.tech is an independent, free-to-use typeahead service used by several atproto apps today
if you don't know what typeahead is, or why it matters, click this link

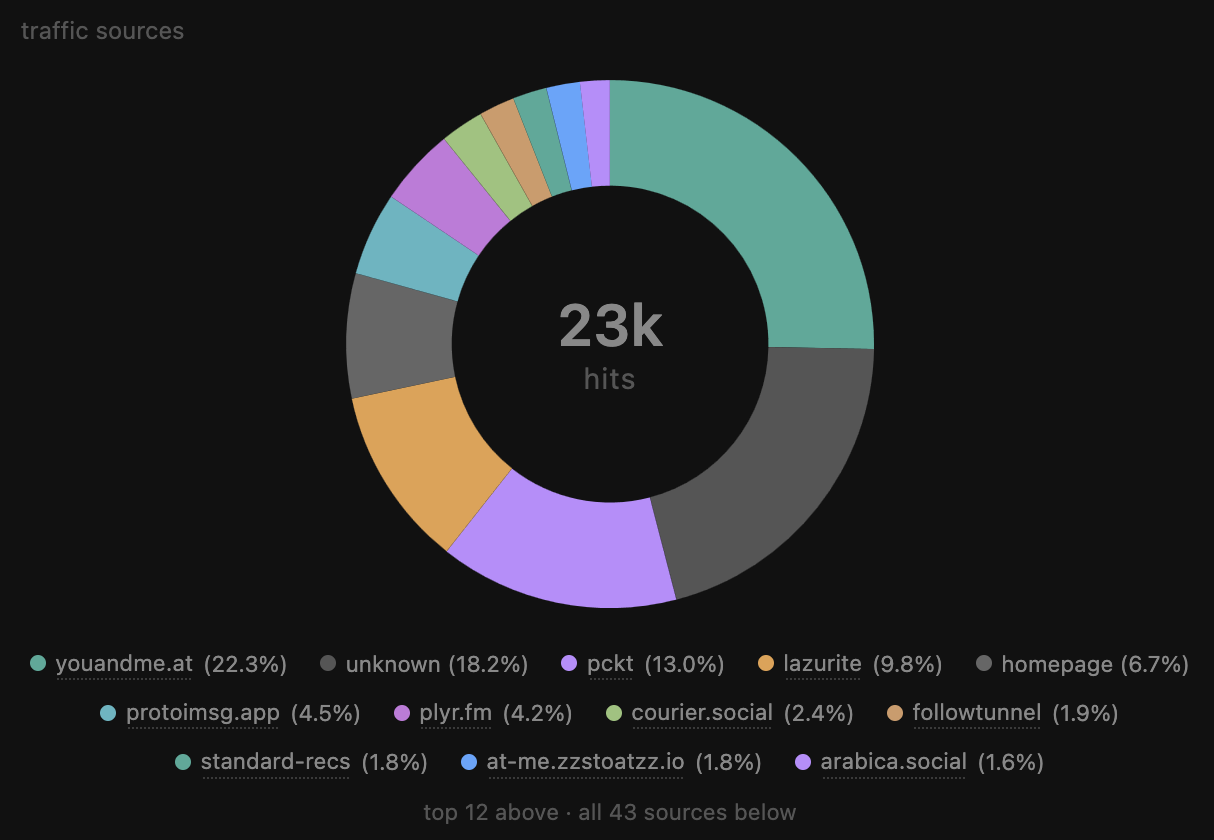
operating it thus far has been not the worst! i seeded the index by listening to select collections from jetstream and following bsky moderation events. i use turso.tech bc it rocks and i synced a read-replica to the backend machine to avoid extra turso reads... same playbook as pub-search.. which was fine until it was not!

yes. yes, it was. ty brookie.blog for reporting! (pckt is our second biggest user!)
the more i looked at why it was broken, the more i realized i had a ton of work to do!!
that is, the backend was just totally not well thought out and needed a redesign.
so Saturday afternoon, i accepted the moral defeat of an emergency bsky proxy and started rewriting the backend and storage layer of the service from the ground up.
as i write this (Tuesday afternoon), typeahead.waow.tech is once again independent! i'll go into how that works after i explain what sort of rat's nest i had built for myself here.
the naivete of good ol' FTS
the original architecture treated typeahead as a dynamic search problem. every keystroke fired a query against a Full Text Search (FTS) table. this broke down in two distinct ways
- in SQLite FTS5,
(is a grouping operator in theMATCHgrammar. our code passed lightly-sanitized user strings directly to the database. typingfig (created a malformed expression; SQLite threw an error, the application swallowed it, and the account silently vanished from results. furthermore, incremental sync was actually dropping and inserting 5.9M rows every cycle. the FTS table was empty for up to 20 minutes at a time, meaningfig (would have returned an empty result set regardless.
- an FTS query ranked by BM25 over a common prefix like
alex*requires anO(corpus)scan. scoring the entire match set took 1.8 seconds, compared to 67ms for a simple unranked limit. introducing a read pool didn't solve this; under load, every connection was quickly pinned by 1.8-second corpus scans until the wait budget expired and threw a 503. worse, SQLite serializes writers — so the 5.9M-row rebuild held an exclusive lock the whole time, and every read it was meant to serve just queued behind it. the system was choking itself while trying to heal! not ideal
mantra!
no request may do work proportional to corpus size. tuning pool sizes and timeouts cannot save an unbounded query plan. eradicate the request-time corpus scan entirely!
i also baked in a couple constraints for myself:
- perf rivaling or beating bsky endpoint
- cheap to operate! even if the atmosphere quadrupled in size tomorrow
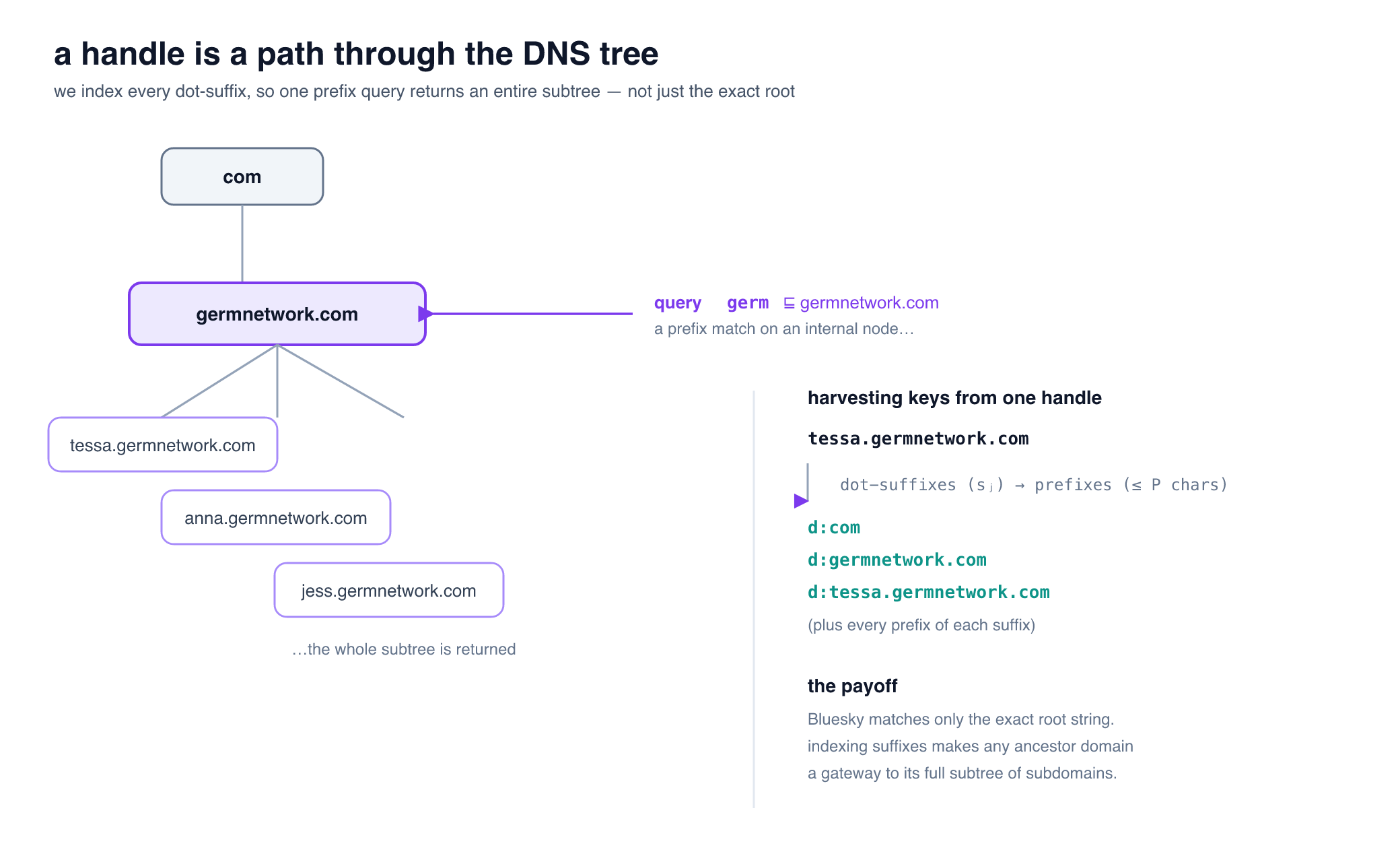
q=germnetwork.comshould returngermnetwork.comand*.germnetwork.com
dominating domain suffixes (the d: index)
tearing down and rebuilding this was also an excuse to fix a product "shortcoming" the old index inherited straight from bluesky, the one anna called out about suffixes!
i had hacked my way to supporting this before, but now paying dearly for these hacks!
an atproto handle is a DNS hostname: a dot-delimited sequence of labels h = ℓ₁.ℓ₂.⋯.ℓₖ. the old h: index only stored start-anchored prefixes, where matching meant q ⊑ h. since tessa.germnetwork.com doesn't start with germ, it was invisible. we needed prefix matching anchored at every "label boundary".
we defined dot-suffixes sⱼ = ℓⱼ₊₁.⋯.ℓₖ and built the d: namespace:

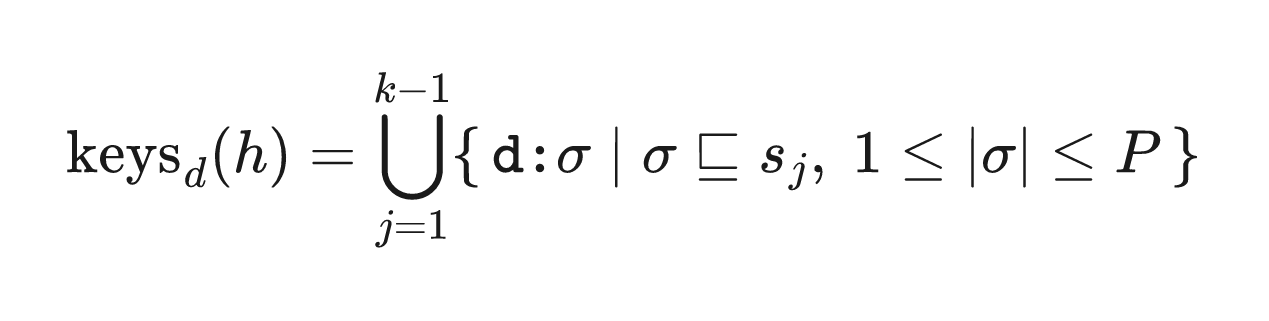
now, h = tessa.germnetwork.com generates keys for germnetwork.com and com. the search is a strict union of bounded point-lookups (at most 4 keys), returning a pre-computed top-N list. it is strictly O(1) in corpus size.

the cost decoupling
computing every suffix boundary generated a massive amount of keys.
build emissions (E) count every uncapped (key, DID) tuple:

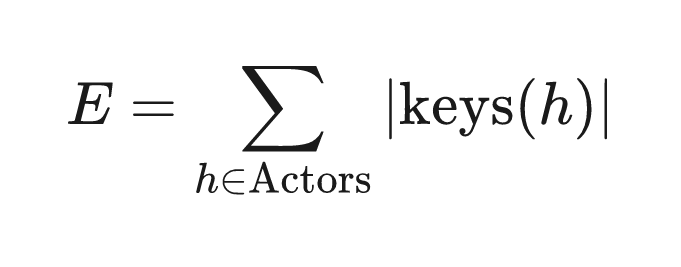
the d: term roughly doubled per-handle emissions, driving total build emissions from 144M to 244M (+69%). this spike in write volume is what temporarily exhausted our scratch disk.
however, the served artifact (A) only stores the top-N capped rows:

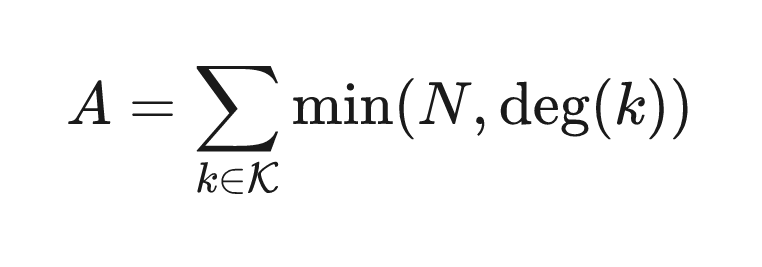
millions of handles end in .bsky.social, but they all collapse onto the exact same d:bsky.social key, strictly capped at N. our distinct keys barely moved. the served artifact grew by exactly +0.9%.

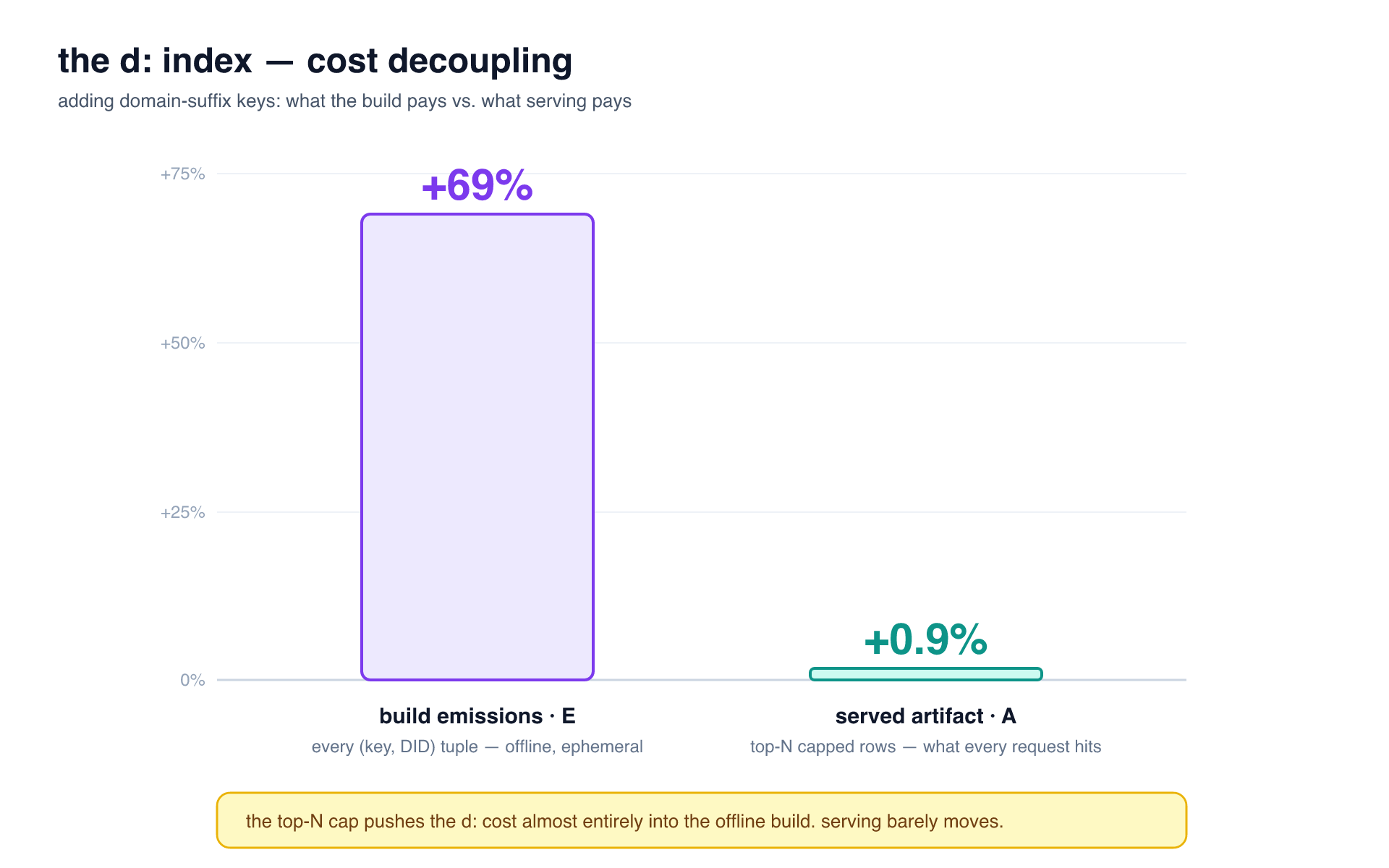
by projecting the data through a top-N cap, the d: index became practically free to serve at scale, pushing the computational cost entirely to the offline build phase.
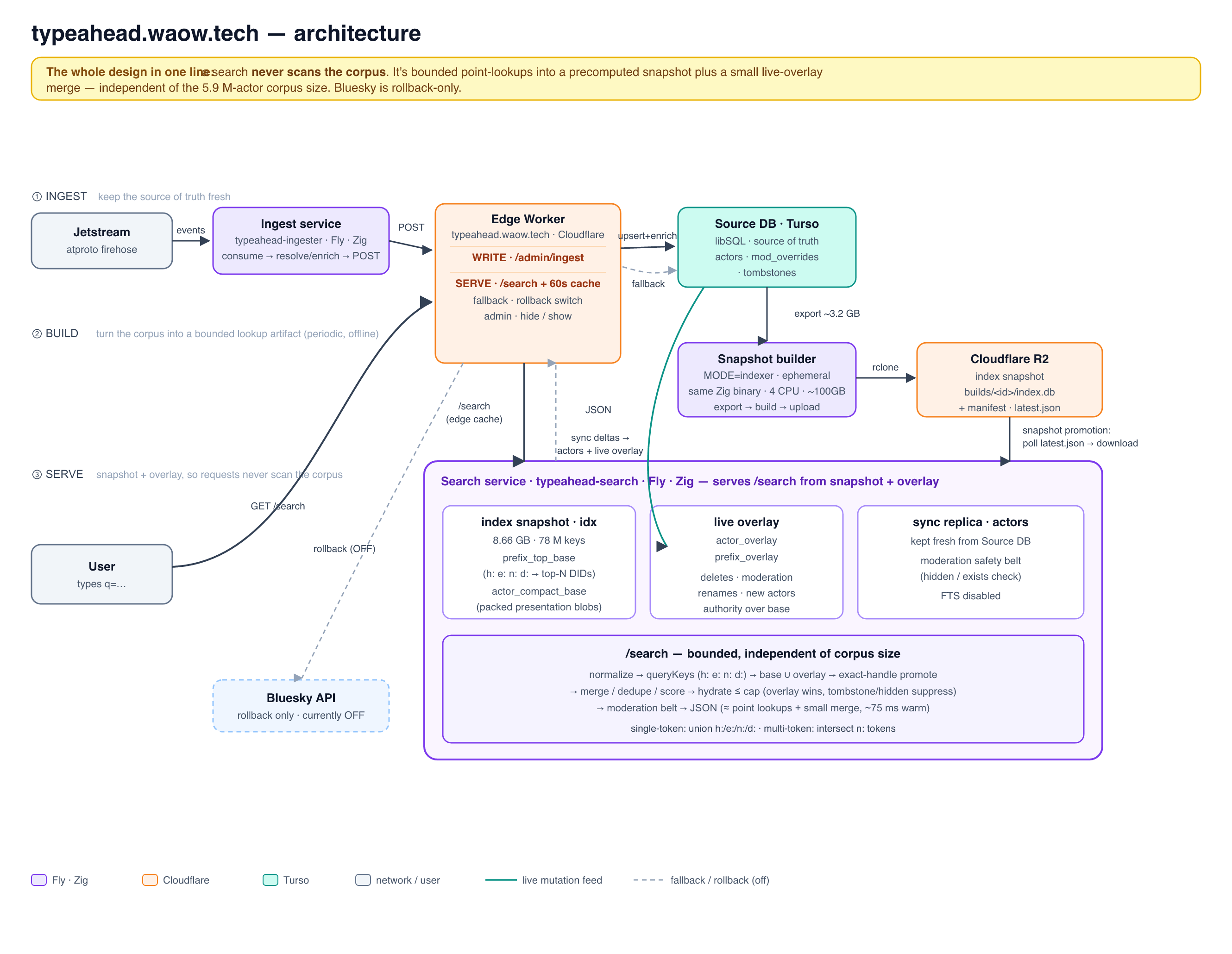
move it offline!
we stopped treating typeahead as a request-time search problem and made it an offline index-build with a live overlay for immediate network updates. a new build doesn't replace the live one until it passes a few checks: the search service downloads it from R2, verifies its sha256 against the manifest, confirms the schema is what it expects, and runs a handful of sentinel queries — handles it knows should be there. only if all of that passes does it atomically swap the new snapshot into the read pool; if anything fails, it keeps serving the current one.
here's an overview of the architecture we landed on!

cheap to operate? (constraint 2)
the read-replica i set up early on kept reads local / cheap — that part wasn't really the issue. the problem was just that O(corpus) is irreducibly painful. every keystroke did work proportional to the entire corpus, so "keeping up" meant a bigger and bigger box that would still wedge under load.
now each search is a handful of bounded point-lookups into a precomputed, top-N-capped index. serving then collapses to one modest Fly machine — a shared-cpu-4x with 2GB of RAM and its 30GB volume, about $18/mo all in. i have turso scaler tier at ~$30/mo that i use for several things including typeahead and pub-search, and now typeahead's contribution to usage limits there is pretty small.
my bet is that ~$18 is flat w.r.t corpus size. the atmosphere can quadruple and the search bill shouldn't rise too much — the box answers point-lookups whether the index holds 6 million actors or many times that. the only thing that grows with the network is the offline build, and that's batch work i can schedule, throttle, and (next) gate behind a quality floor to keep sub-linear
a breadcrumb for later: the sync layer underneath all this is the least-principled part of the system, and Hubble is already doing it properly. two things worth stealing when my ingest races get gnarly — serializing all of a repo's updates through a single lane so commits, resyncs, and status changes can't race, and its actual vocabulary for repo lifecycle (active, deactivated, tombstoned, desynchronized, resync-needed). i haven't adopted any of it yet. and if it matures, it could become the sync source feeding this index instead of my jetstream→turso plumbing — it mirrors the whole network; typeahead just needs enough actor state to answer one query fast. different jobs, but i've got plenty to learn from how they model theirs.
check out typeahead.waow.tech/stats for more!